Datasets
Contents
9.5. Datasets#
9.5.1. Wikipedia’s list of machine learning datasets for research#
Did you know there are ~56 MILLION Wikipedia pages in total?
Did you also know that some of those pages contain information that are beyond the wildest dreams of certain people but are just buried too deep inside?
Here is one of those pages that outline some of the best datasets on machine learning research and with links to their papers👇 https://en.wikipedia.org/wiki/List_of_datasets_for_machine-learning_research
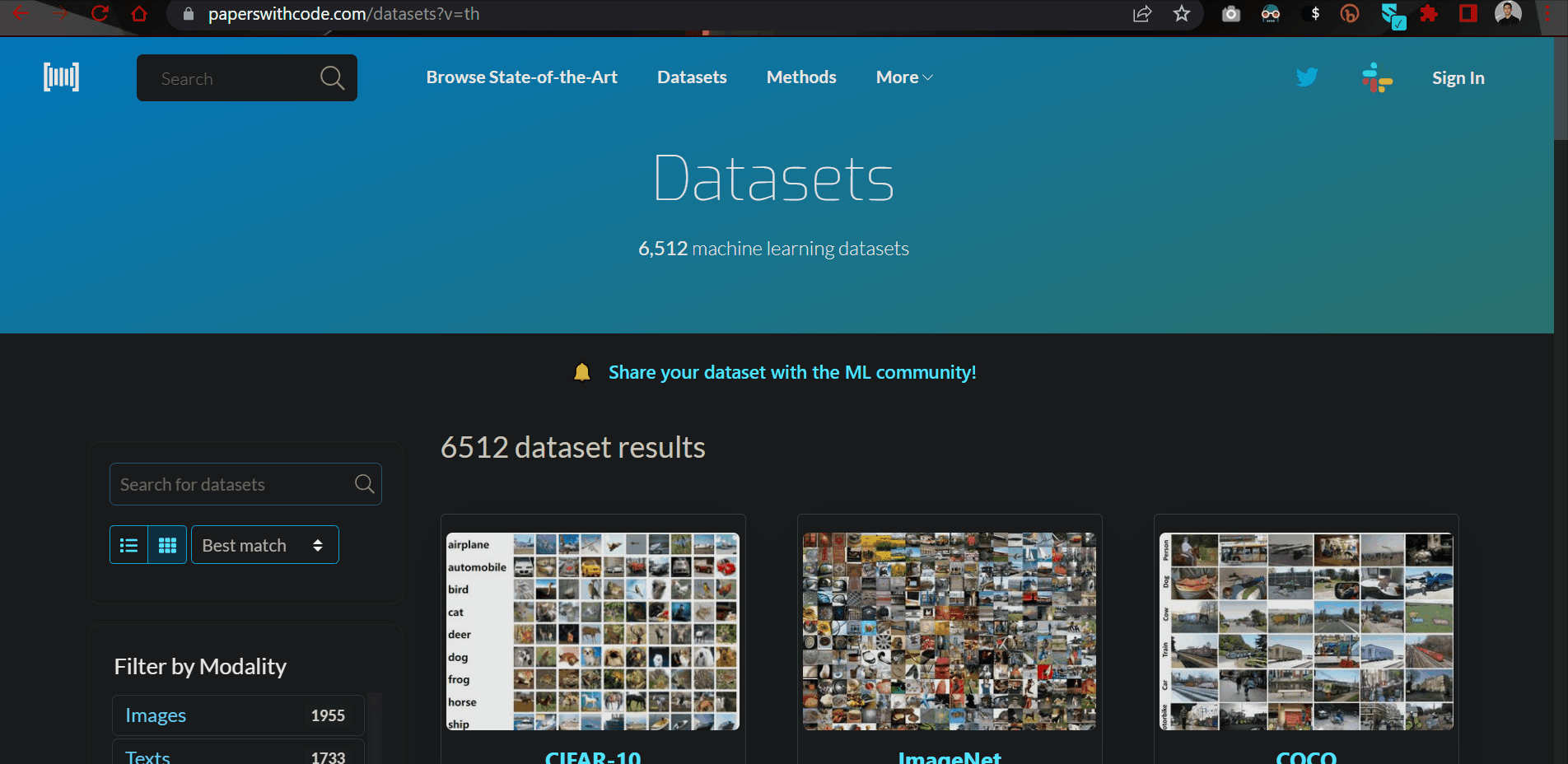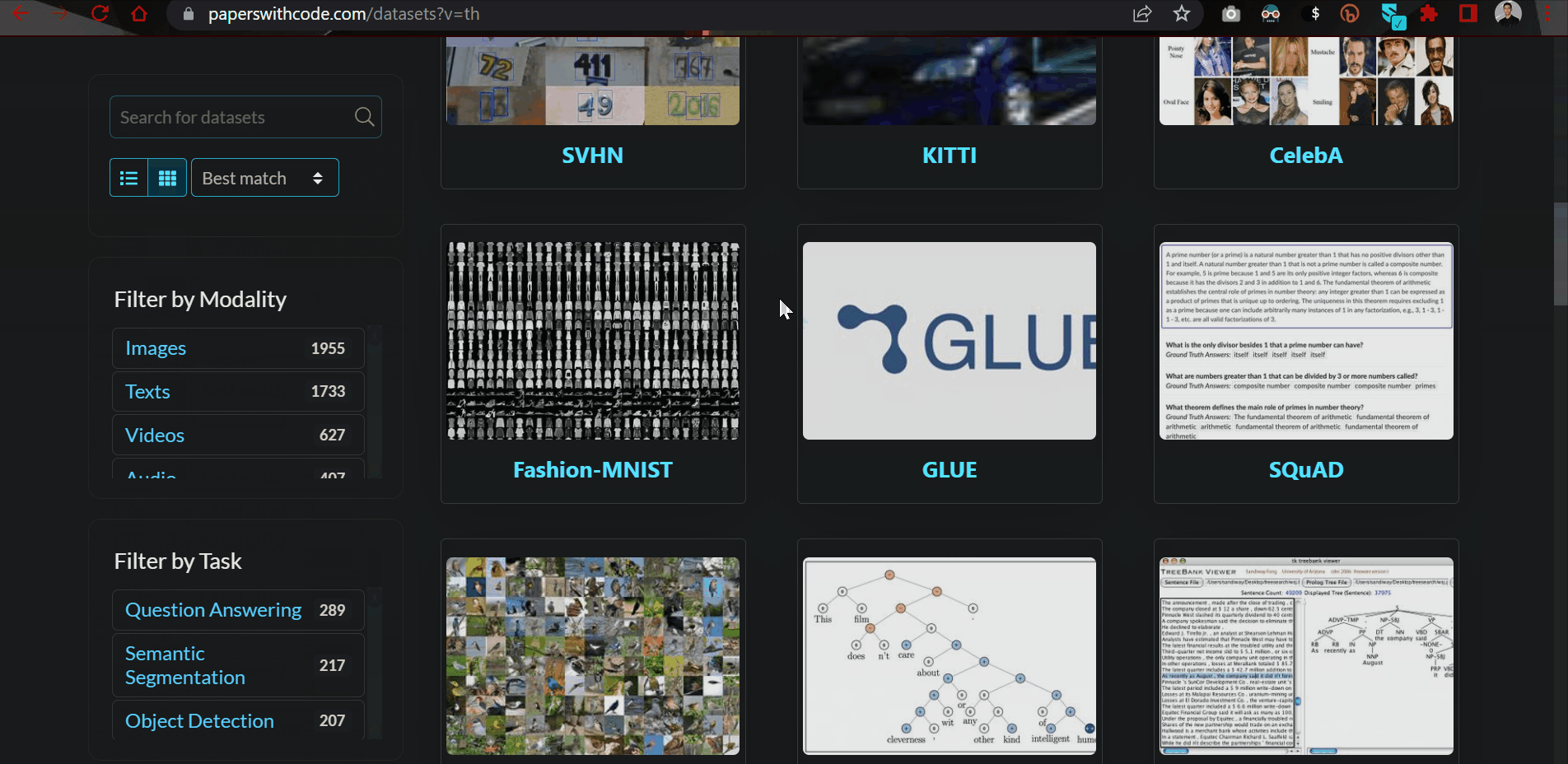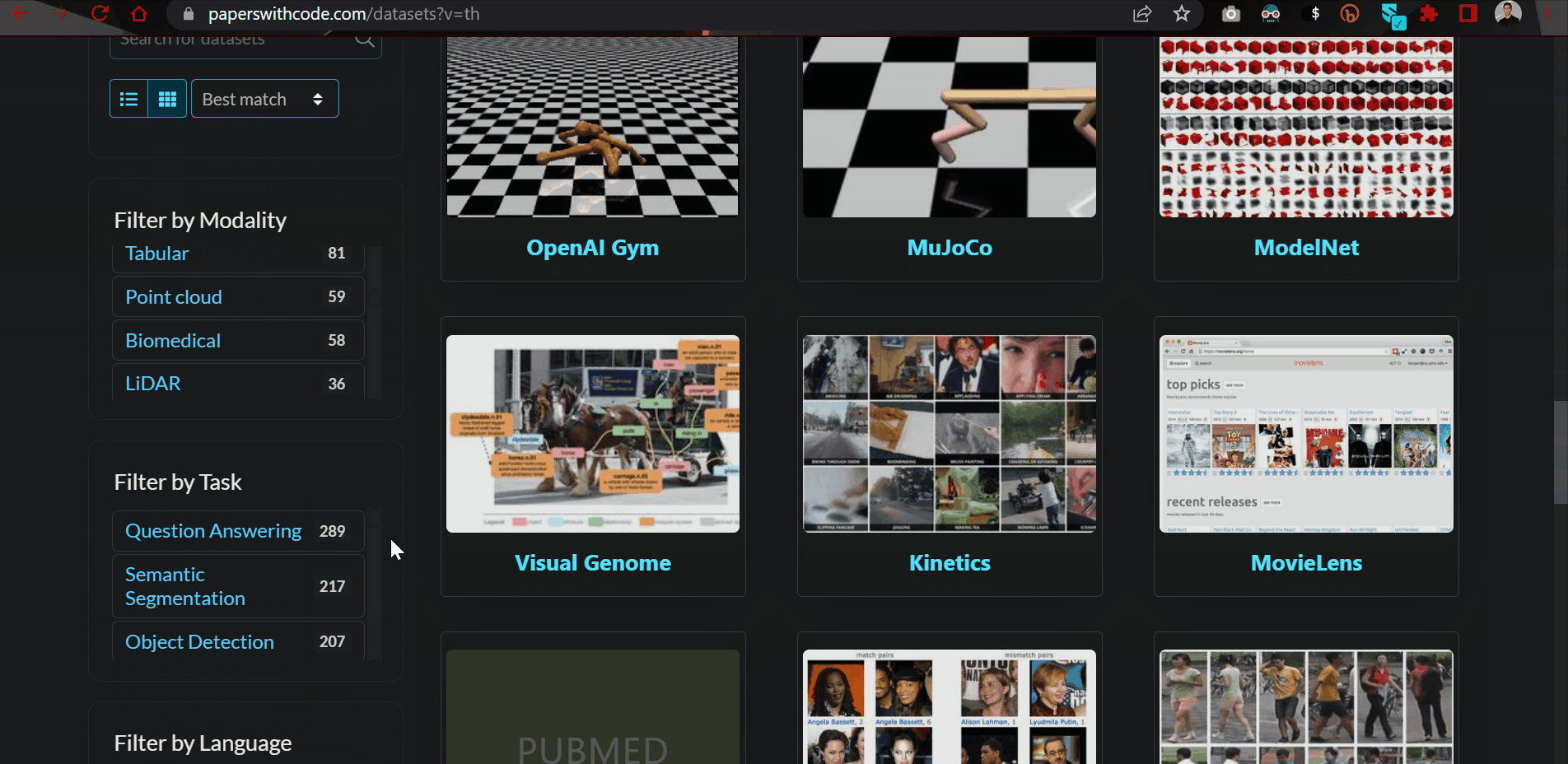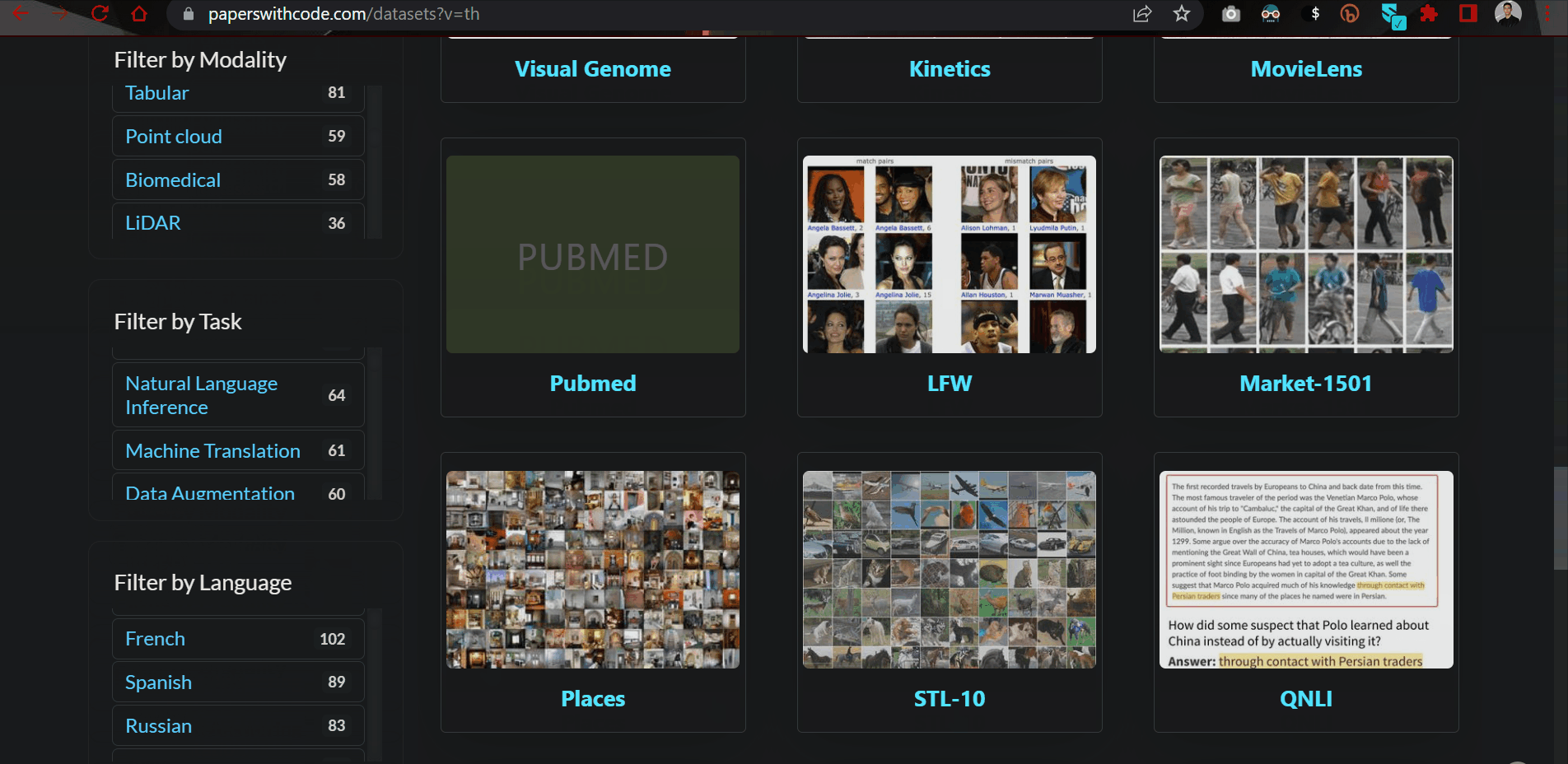
9.5.2. Papers with Code datasets#
Want to get your hands on high-quality datasets used in cutting-edge research?
The Papers with Code dataset has a curated list of over 6500 such datasets with controls to filter by data type, task and language.
Link to the source: https://bit.ly/3QP50pH
9.5.3. CT-GAN - generate synthetic data from existing sources#
There are so much more private datasets than open-source. But private datasets can be shared too, if you make sure to preserve the anonymity and fidelity of the data.
One of the best tools to do this is the CTGAN library, which when fit to a dataset, can generate a synthetic dataset with the same distributions and features as the original but hiding any sensitive information.
The resulting dataset would be completely unrecognizable but still have the statistical properties of the original.
The CTGAN library is based on the “Modeling Tabular using Conditional GAN” paper. Link to the Python API and paper in the comments👇

CTGAN Python package: https://github.com/sdv-dev/CTGAN
CTGAN paper: https://bit.ly/3RgoPXw
9.5.4. Google dataset search#
Google has a custom domain for dataset search!
Once you type in a keyword, the search will crawl across hundreds of dataset sources to find the best matches. It has got filters for data format (structured, unstructured), usage rights, topics and when it was last updated.
I found the results of this sub-domain much cleaner than plain old Google Search, which always contains unnecessary pages and slows down your dataset search.
Link to the tool in the first comment👇
Link to the tool: https://datasetsearch.research.google.com/
9.5.5. OpenImages - GoogleAPIs#
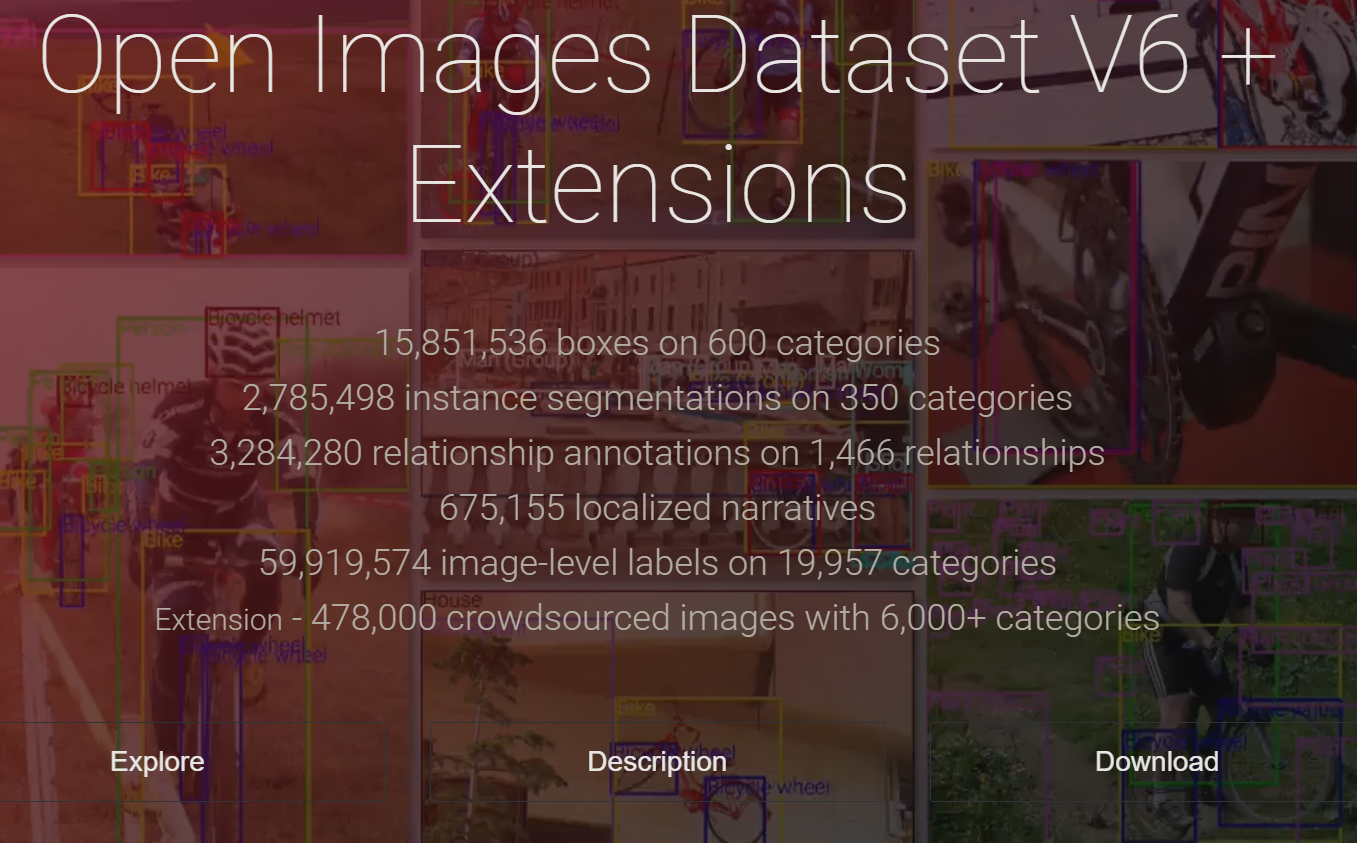
Close to 100 million images, with ~20k categories annotated!
Open Images Dataset V6+ is an open-source repository of almost 100 million high-quality images with over 20k categories annotated for image classification. There are also special images for instance segmentation, object detection (wrapping boxes), etc.
The website has filters for keyword search and download.
Link: https://bit.ly/3Q1Nu0K
9.5.6. changedetection.io for web scraping#
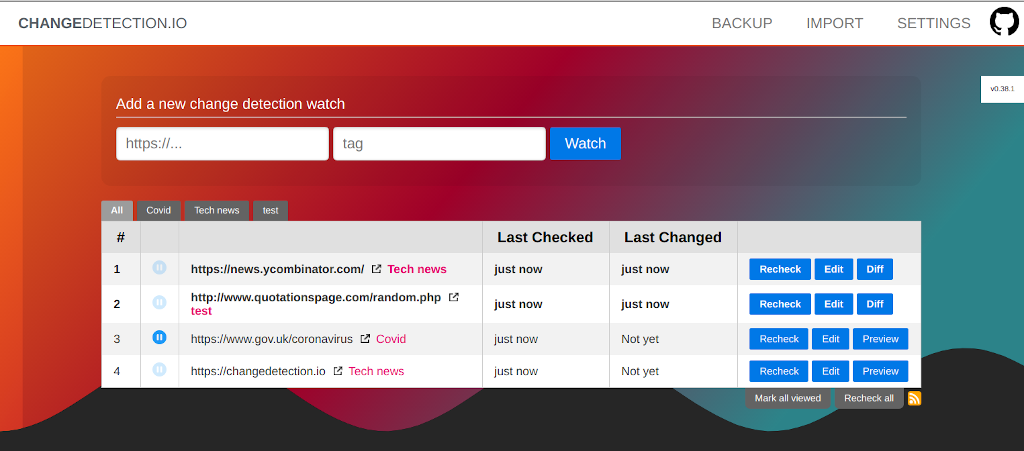
One of the heavy challenges of web scraping in data science is websites changing their HTML/JavaScript code.
A single class name change or the introduction of a new tag can totally break your scheduled web scrapers. And the hardest part is that the website change their internal markup so frequently that you don’t even know what broke your scraper.
For such cases, you can use the open-source changedetection [dot] io to watch out for website changes. By simply clicking the “Diff” button you can see what changes and update your code accordingly.
Link to the tool in the comments.
Link to the tool: https://changedetection.io/